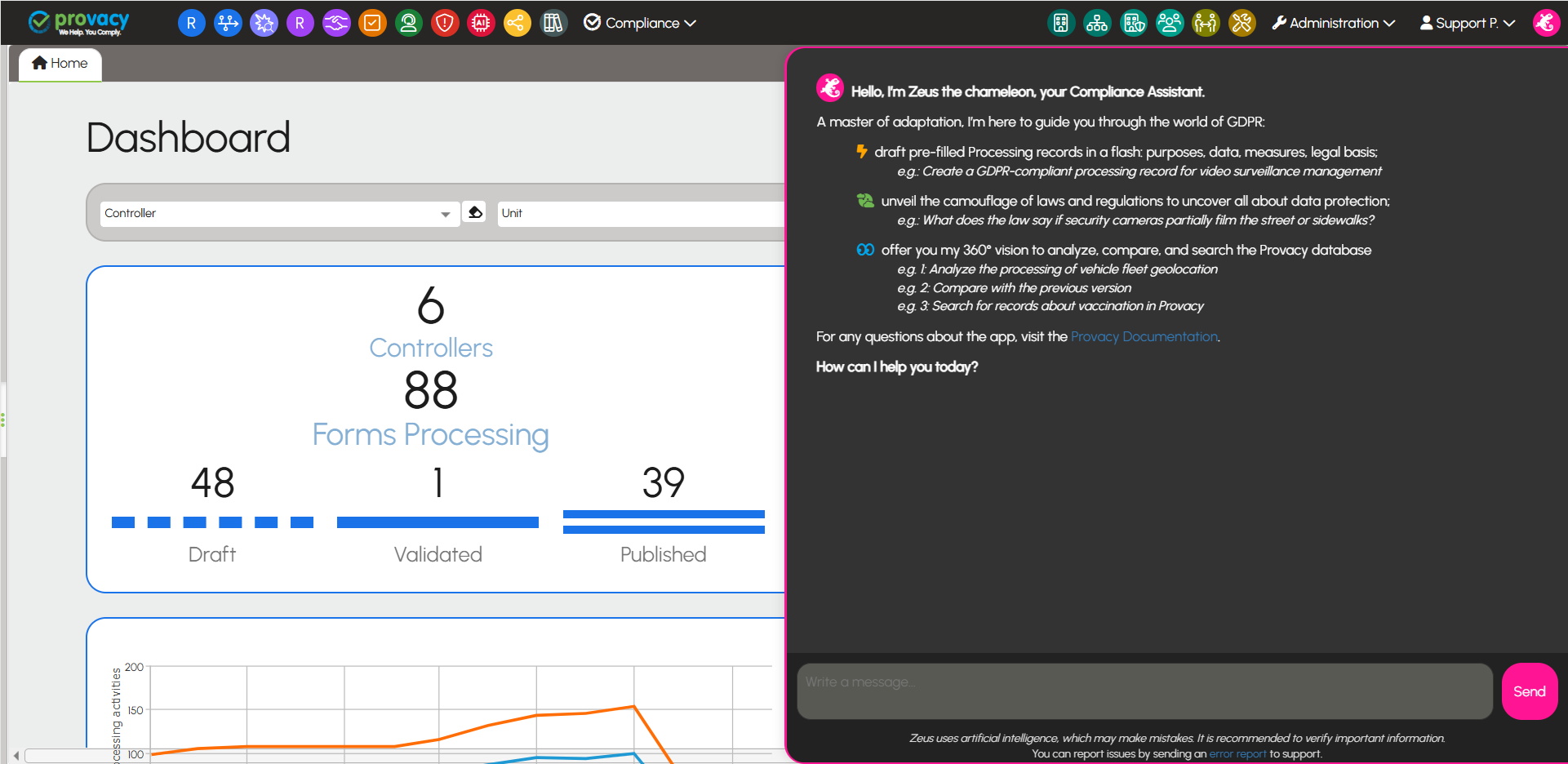
Zeus, the AI assistant by Provacy
Compliance accelerator
Designed to save you time, Zeus the AI assistant transforms GDPR complexity into useful, simple, and concrete actions:
- Smart draft creation
- Instant analyses and compliance assessment
- Precise comparisons
- Expert search
Beyond its specialized functions, Zeus is a full conversational assistant, always ready to answer your questions, anytime.
An assistant++ for the price of a chatbot
Zeus stands out thanks to its ultra-light architecture, which dynamically adapts to each interaction. It uses only 800 tokens at rest, in minimal configuration, and can deploy up to 3,900 tokens to perform its most complex tasks — such as creating or updating processing records, leveraging its expert knowledge of the GDPR. Where others just chat, Zeus acts, analyzes, and proposes solutions.
A healthy mind in a healthy body
Agile and sharp, Zeus thrives on simplicity, making it easy to work with. Without any special training or tedious fine-tuning, it naturally integrates into its environment. Compatible with the best models on the market (GPT-4.1 / mini, Gemini, Mistral Large, etc.), it even accepts your own API key for full control.
To fully harness its potential, a minimal context of 32k tokens is recommended (3k for its framework, leaving 29k for conversational tracking). And of course, the larger its playground, the better it performs.
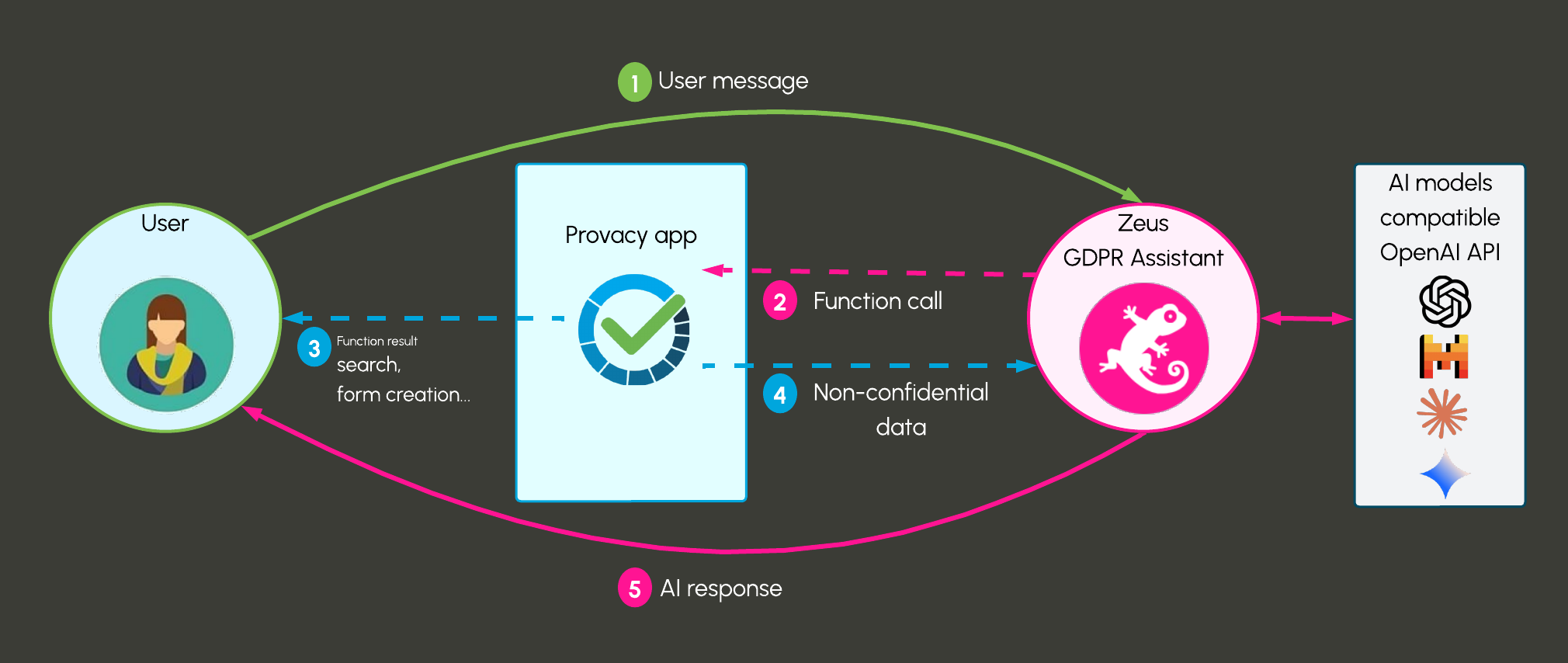
No confidential data, such as the names of your software, tools, or third parties, is shared with the AI model.
Prices
| Option | Price excl. VAT / year |
|---|---|
| Assistant without API key provided | 1200 € |
| Assistant + API key | 1800 € |
Prices and transaction limits depend on the AI models used. The €1,800 excl. VAT/year price includes:
- Management of your API key(s): €360
- AI model usage cost: €20/month of transactions, totaling €240
The volume can be adjusted according to your needs, and the price will be adapted accordingly based on the model used.
Example Models and Usage Limits
Here is an estimate of possible use cases for €20 tokens/month based on GPT and Mistral models. The GPT-4.1 model is currently recommended for optimal assistant performance.
| Model | AI Quality | Input €/k | Output €/k | Total €/k (60/40) | Approx. Tokens Available | Estimated Analyses (10k tokens each) | Recommended Users |
|---|---|---|---|---|---|---|---|
| GPT-4.1 | 🟢 Excellent | 0.01 | 0.03 | 0.018 | ~13.3 M | ~1300 calls | 1 (max 2) |
| GPT-4.1 Mini | 🟡 Good | 0.006 | 0.012 | 0.0072 | ~33.3 M | ~3300 calls | 3 (max 4) |
| Mistral Large | 🟠 Above Average | 0.004 | 0.012 | 0.0088 | ~27.3 M | ~2700 calls | 2 (max 3) |
| Mistral Medium | 🟠 Average | 0.002 | 0.006 | 0.0036 | ~66.6 M | ~6600 calls | 6 (max 8) |
Comparison
| Criterion | Zeus (Provacy) | Classic AI Systems | Heavier AI Systems |
|---|---|---|---|
| System Size | 800 to 3,900 tokens | 2,000 to 5,000 tokens | 5,000 to 10,000+ tokens |
| Governance Rules (Ease of Understanding) | Clear and simple, adapted for non-expert users | Often complex, technical jargon or internal AI terms | Very detailed, sometimes hard to follow without expertise |
| Typical Use Cases |
Deep GDPR expertise, comparative analysis Pre-filled record creation (AI suggestions + user edits) Step-by-step guided updates with validation |
Simple FAQ, info extraction, short text generation Standard assistance, no granular validation |
Complex copilots managing multi-object and multi-process workflows Cross-document analysis, full workflows |
| Data Compliance and Security |
Explicit user consent for data transmission Full data visualization Final granular validation of updates No AI exchange storage, session-only data |
Variable, often unclear data handling and storage Little or no granular user validation |
Highly variable, often long-term storage and automated analyses More enterprise-focused with specific constraints |
| AI Model Compatibility |
Compatible with GPT-4.1, Mistral Large, Gemini, other high-performance LLMs Key provided or client key as needed |
Often dependent on a single or limited model | Sometimes closed, dependent on specific AI vendor |
| Integration and Maintenance Flexibility |
Modular architecture, tools auto-loaded/unloaded Smooth session management, lightweight context retention (20 messages) |
Generally static, not optimized for long interactions | Can be complex to maintain, often heavy integration |